In the previous blog post I looked into how Model Context Protocol (MCP) servers are gaining traction and how they simplify the interaction for developers and well known tools.
In this blog post I look into how to build an MCP server for Percona Everest - an open source cloud native database platform. The goal is simple - create the MCP server that will expose Percona Everest to Large Language Models or AI agents through tools (by calling the API).
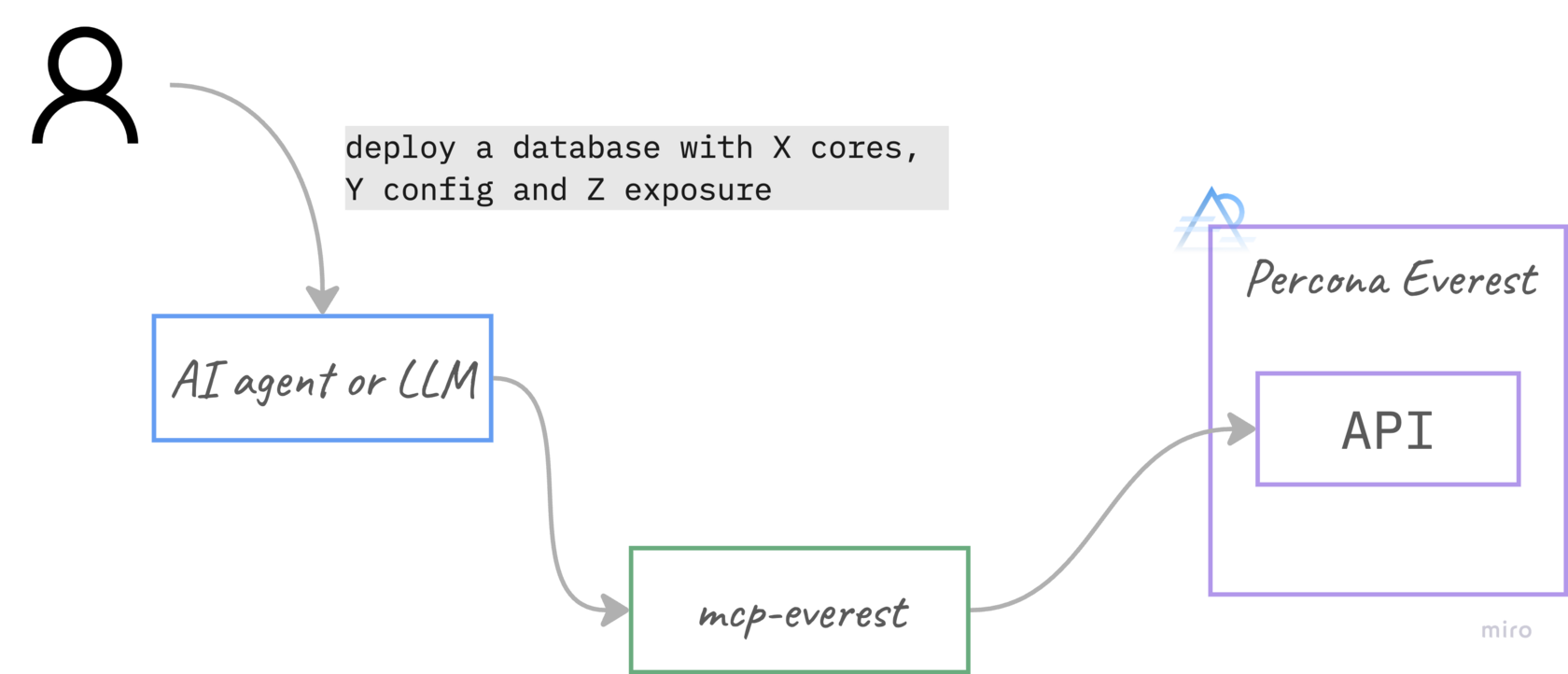
Code is available in github: spron-in/mcp-everest
Note: It is an unofficial MCP Server for Percona Everest. It has limited capabilities and is not pushed to the UV registry.
Refresher on MCP
Model Context Protocol (MCP) is like a standardized language that helps different AI tools (like language models, code interpreters, and retrieval systems) talk to each other smoothly. Instead of each tool having its own unique way of communicating, MCP provides a common set of rules and formats for exchanging information like messages, prompts, tool calls, and resources. This makes it easier to build complex AI workflows where various components can work together seamlessly, leading to more powerful and versatile AI applications. Think of it as the universal translator for the AI ecosystem.
Prepare Percona Everest
Percona Everest runs in Kubernetes, so having a k8s cluster is a prerequisite. Once you have the cluster, install Everest by following the documentation. For simplicity, I recommend the helm chart method. That way installation is just one command.
Once Percona Everest is installed, we need to expose it. As it is not a production environment, it is fine to connect to Everest via port-forwarding:
kubectl port-forward svc/everest 8080:8080 -n everest-systemGet the admin token from the secret:
kubectl get secret everest-accounts -n everest-system -o jsonpath='{.data.users\.yaml}' | base64 --decode
admin:
passwordHash: SOME_PASSWORD_HASH
enabled: true
capabilities:
- loginOpen the WebUI in the browser and enter the credentials - admin/SOME_PASSWORD_HASH.
Percona Everest API
Some aspects of Everest API are not that obvious and I had to battle through. Here are some of them:
Endpoint URL
It was not obvious for me from the API documentation where should I connect to use the API. In the documentation that Percona provides there is an example.com placeholder. Looking deeper in the docs I noticed the following:
Access the Everest UI/API using one of the following options for exposing it
Aha, so endpoint for API is the same as WebUI. Something like http://127.0.0.1/v1/SOME_ENDPOINT would do.
JWT Authentication
I was not able to find anything about API authorization. When I tried to call the API endpoint without any auth, I got the error:
{"message":"missing or malformed jwt"}Got the hint - I need a JWT token. Obtain JWT token from the Web UI after logging in. The token is stored in the everestToken variable within the browser's local storage.
I sent a Pull Request to Percona docs to add this note.
API documentation
GET endpoints are quite easy, whereas when I tried to create a database with a POST request using this documentation section - I failed multiple times. At first it is quite hard to understand which fields are required. In documentation there are some fields that are hidden under collapsed menus. Then some of the fields are not properly marked, as I learnt that “metadata.name” is required to create a cluster. Also requests for storage and memory are better set in strings (“10Gi”), as it is unclear what integer is for.
But enough with the rant, eventually I figured it out after a few attempts.
Create an MCP server
There are numerous SDKs (1, 2) to create MCP servers. As I’m more proficient with Python, I will use FastMCP. This blog post will become unmanageably long if I go too deep into details of each file. To avoid that I will explain only the purpose of each and explain important lines of code.
It is the wrapper with requests to call Percona Everest API endpoints. Our MCP tools use it. The file is easy to understand and modify.
Defines environment variables that are essential to connect to Percona Everest API. Nothing interesting here, just standardizing the env vars.
This is the core. This is the file where we define the MCP server with FastMCP:
mcp = FastMCP(
MCP_SERVER_NAME,
dependencies=deps,
)We tell it how to connect to Everest API:
# Initialize Everest client using config
everest_config = EverestConfig(
host=config.host,
api_key=config.api_key,
verify_ssl=config.verify_ssl,
timeout=config.timeout
)
everest_client = EverestClient(everest_config)What tools do we have:
@mcp.tool()
def list_database_clusters(namespace: str) -> List[Dict[str, Any]]:
"""List available database clusters in the specified namespace."""
logger.info(f"Listing database clusters in namespace '{namespace}'")
try:
clusters = everest_client.list_database_clusters(namespace)
logger.info(f"Found {len(clusters)} database clusters")
return clusters
except Exception as e:
logger.error(f"Failed to list database clusters: {str(e)}")
return {"error": str(e)}
And that is it. Our minimal MCP server is ready.
Try it out
Environment variables
To connect to Percona Everest make sure you set proper environment variables that we defined in mcp_env.py. See more details in README.md.
Inspector
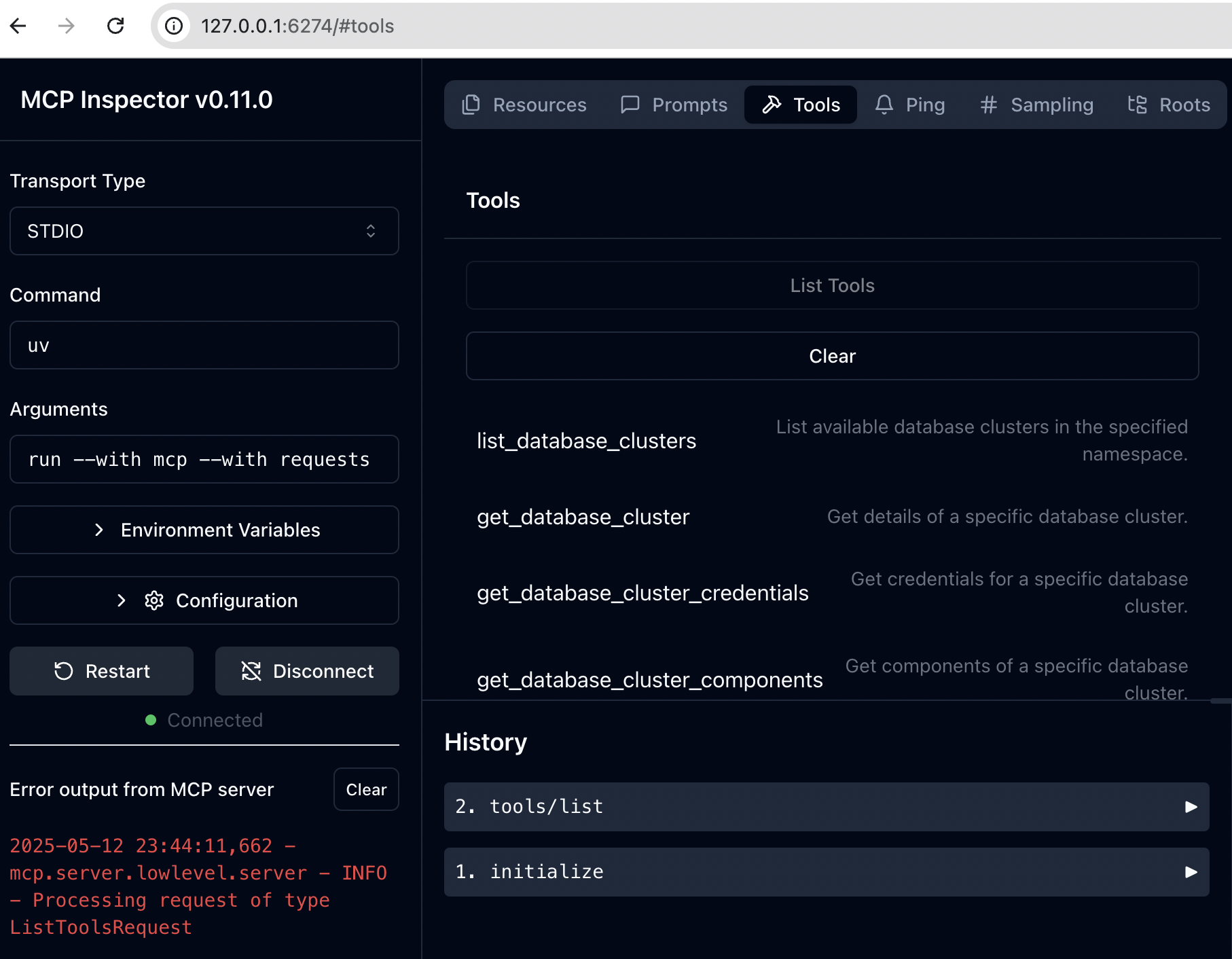
There is an MCP inspector - a developer tool for testing and debugging MCP servers. It has a nice UI, and requires NodeJS.
Run the following in the github repo folder:
% mcp dev mcp_everest/mcp_server.py
Starting MCP inspector...
⚙️ Proxy server listening on port 6277
🔍 MCP Inspector is up and running at http://127.0.0.1:6274 🚀Connect to Inspector’s WebUI at http://127.0.0.1:6274.
If you go into the tools section, you should see the tools that we defined in the mcp_server.py file.
Client example
Claude Desktop or Cursor are MCP Clients that talk to Servers with LLMs. They execute commands via tools or enrich context from resources. It is easier to use MCP Servers when they are officially published somewhere. As it is an unofficial server, I will not publish it. But I still want you to show something more than MCP Inspector UI.
Meet mcp_client.py - it has just one purpose - simulate an MCP client with LLM (Gemini in my case).
There are two prompts that we have predefined in the code:
# prompt = f"How many database clusters are there in the namespace 'default'?"
prompt = f"Create pxc cluster in namespace everest with 1 node and 10 GB storage, name it mcp-test"They are self-explanatory and mimic the user prompting the model or talking to agent.
Run it:
python mcp_client.pyDepending on the prompt, you will see how LLM talks to the MCP server to address the user inquiry. The final response from the script I got was:
Okay, I will create a PXC database cluster named 'mcp-test' in the 'everest' namespace with 1 replica and 10Gi storage.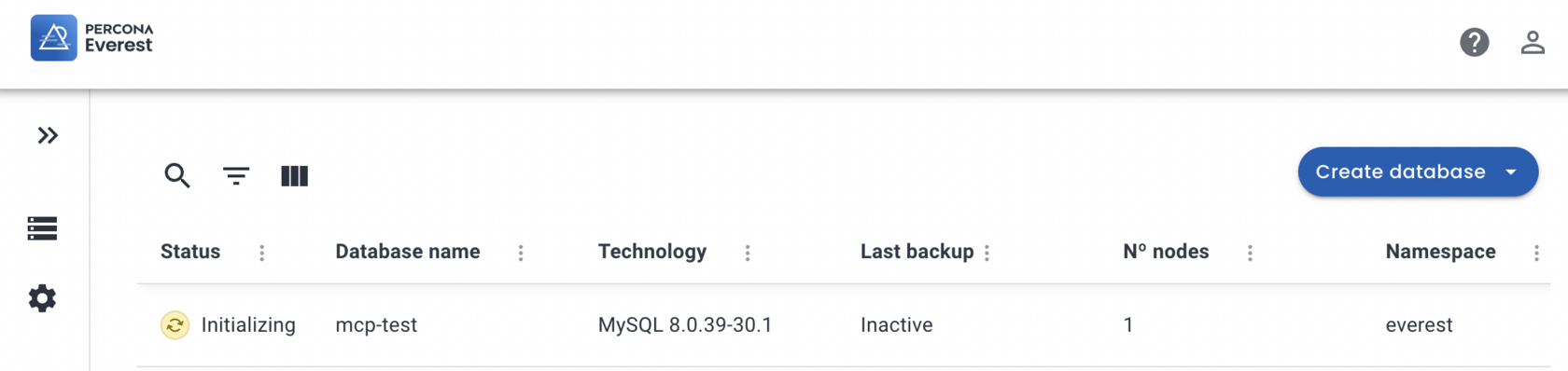
What is next
In general, the number of MCP Servers and their traction continues to grow.
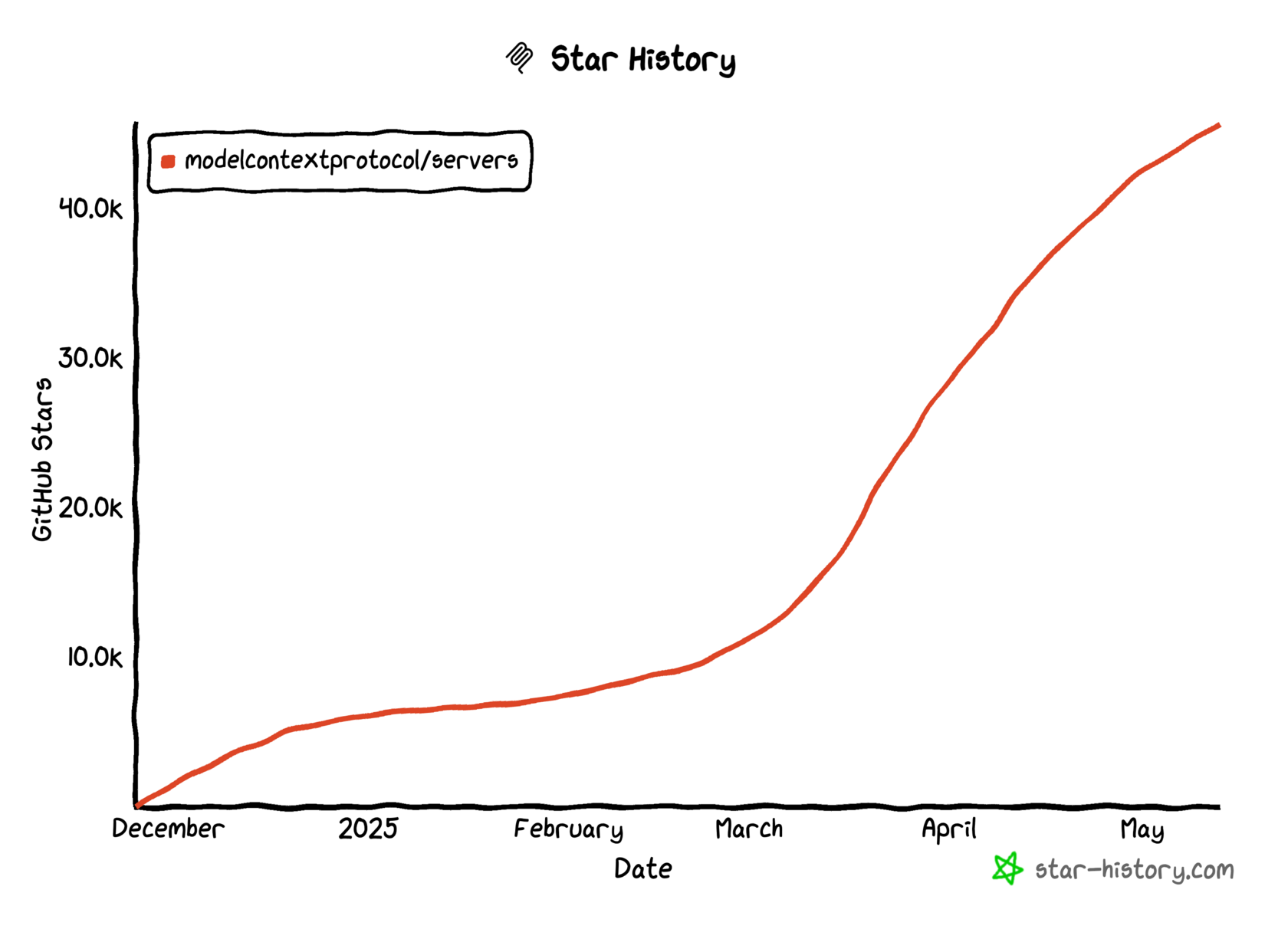
I’m still hesitant about MCP real world use cases. IDEs like Cursor are adopted by millions of developers and for sure somebody is using MCPs to simplify their lives, but to what extent.
What I’m sure about is that the combination and synergy of various MCP servers are going to be a winning strategy. For example, users can deploy databases using mcp-everest, talk to database with Postgres MCP and troubleshoot Kubernetes with mcp-server-kubernetes. Playing with these combinations will move vibe coding / operations to a new level of fun.
As for what is next for mcp-everest, I laid out some ideas in README. Hope to see some official Everest MCP with extended endpoints coverage.