On my geek Friday I got curious about Generative AI abilities to simulate various applications and APIs. This curiosity immediately sparked an idea to mimic Kubernetes API and provide users with close-to-real responses. I called the project Kaisim - Kubernetes AI Simulator - and started working on a quick prototype at Replit.
The plan was ingenious, a swiss watch:
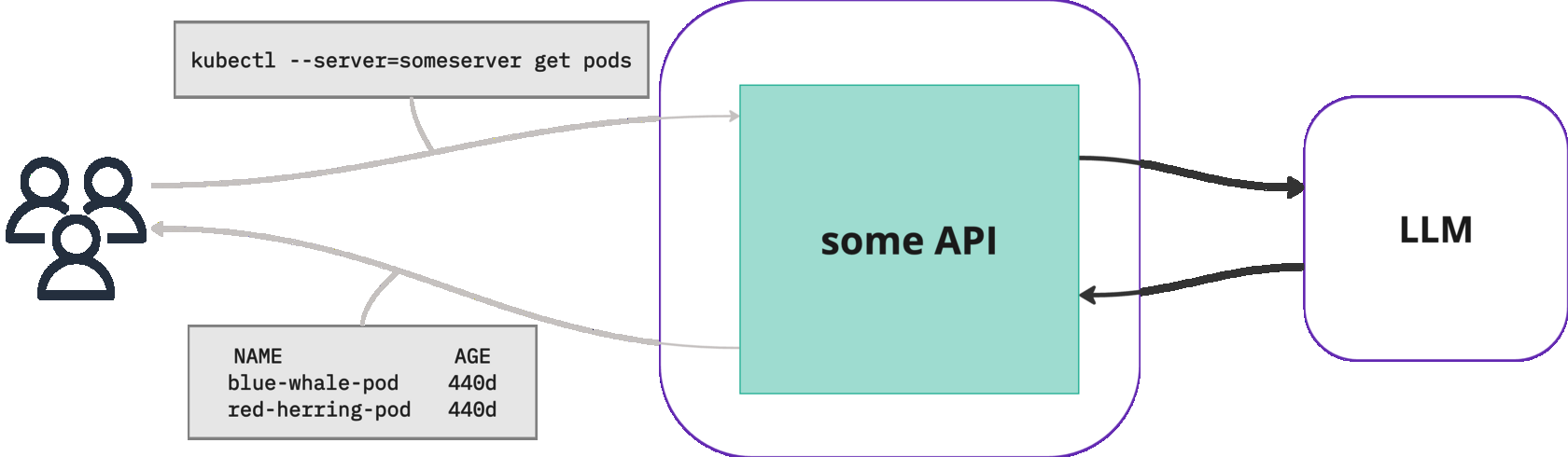
- User: sends a request to our fake API
- Fake API: add some context and send it to a Large Language Model (LLM)
- Fake API: process the response from LLM and sent it to the user
As usual this article was born out of a weird marriage of obstacles and issues faced during development of the fake API.
TL;DR
Try it out at kais.im and see the code at spron-in/kaisim
First experiments
Each kubectl command translates into a call to Kubernetes API. For example, kubectl get pods is going to send a GET request to the following endpoint:
https://k8s_api_server/api/v1/namespaces/default/pods?limit=500Given we know the HTTP method, API endpoint and also can get the data sent to us - can we ask AI to generate a response?
After asking some questions to Gemini on the web and getting decent responses I decided to build a quick PoC with CrewAI. I like agentic frameworks, like Autogen, LangGraph, CrewAI, as they have fallback mechanisms - in case LLM provides a subpar response, they can automatically ask again (reinforcement learning). Not needing to implement this logic myself is a no brainer.
I created the following task, wrapped it into the crew and it worked - I saw proper JSON responses:
kubernetes_api_task = Task(
description=
("You received the {request_type} request to the following API endpoint:\n"
"{api_endpoint}\n\n"
"You should provide the response as if you are a real Kubernetes API. You can imagine resources as we are doing it for educational purposes.\n"
"You can produce responses with 1 to 5 resources in them. In 5% of cases you can provide a proper response that indicates that resources do not exist.\n"
),
expected_output=
("A response to the API request mimicking the response of the real Kubernetes API server. Use creative names for Kubernetes resources.\n"
),
agent=kubernetes_api_agent)
Python script worked as expected:
# Agent: Kubernetes API simulator
## Final Answer:
```json
{
"kind": "PodList",
"apiVersion": "v1",
"metadata": {
"resourceVersion": "12345"
},
"items": [
{
"metadata": {
"name": "mypod-78997",
"namespace": "default",
"uid": "a1b2c3d4-e5f6-7890-1234-567890abcdef",
"resourceVersion": "56789",
"creationTimestamp": "2024-01-01T12:00:00Z",
"labels": {
"app": "myapp"
}
…Wrapping this call into a Flask API produced similar responses. Great!
I did not want to get into user management and decided that all requests to the fake API must have the token. When you run kubectl –token=”SOME_TOKEN” it translates into an Authentication Header with Bearer token. I want a token for mere rate limiting and for future memory store, to keep the “conversation” smooth and interactive.
And now to issues
Now it is time to try with kubectl instead of just querying the API with curl.
1 - certificate signed by unknown authority
On my first run of kubectl –token=”” –server=api.kais.im get pods I immediately got:
Unable to connect to the server: tls: failed to verify certificate: x509: certificate signed by unknown authorityFrankly, I was ready for this. kubectl is known for its own ways of verifying the API certificate. Even if the certificate is valid, you might need to add its Certificate Authority (CA) into kube config. I will not do it for now and just use –insecure-skip-tls-verify flag.
2 - couldn’t get current server API group list
SSL certificate issues are out of the way, let’s continue. On my next run of
kubectl –insecure-skip-tls-verify –token=”” –server=api.kais.im get pods I got the following:
E0314 15:34:42.669635 19999 memcache.go:265] couldn't get current server API group list: the server could not find the requested resourceThis puzzled me for a minute. I’m sure this is too easy to decipher for experienced K8s engineers, but I had to use mitmproxy and look into nginx access logs to understand it. I was surprised that for get pods request there were a few other GET calls:
GET /api?timeout=32s
GET /apis?timeout=32s
GET /apis/autoscaling.x-k8s.io/v1beta1?timeout=32s
GET /apis/autoscaling.x-k8s.io/v1?timeout=32s… and more, 40+ different calls.
What is going on here? It turns out that when you talk to a Kubernetes cluster for the first time, kubectl is fetching cluster “capabilities” and caches them. Usually you can see the cache in the ${HOME}/.kube/cache/CLUSTER folder. Capabilities - a formal description of the verbs, URIs, and request/response bodies tolerated by a given kubernetes cluster, which includes any installed Custom Resource Definitions.
For my simulation API it meant that for a single get pods call, I will need to call LLM around 40 times (at least for the first user’s kubectl run). Suboptimal. So I decided to implement a simple cache for these “capability” API calls. You can find them all in a predefined-cache.json file. It is pretty big - ~10MBs.
- I fetched the result of these API calls from a real GKE cluster
- Put them into the JSON file
- And with init_cache.py put them into PostgreSQL database
- Now when user queries these APIs they are returned from a database / cache
3 - hallucinations / errors
Instead of caching requests to API endpoints that fetch api-resources I tried to run them through LLM. But I was getting weird errors like this:
E0314 17:05:00.114678 40194 memcache.go:287] couldn't get resource list for node.k8s.io/v1: converting (v1.APIGroup) to (v1.APIResourceList): unknown conversionFor some reason LLM thinks that for /apis/node.gke.io/v1 it should return kind: APIGroup instead of kind: APIResourceList. I tried other LLMs and they sometimes still fall into the same trap. There are multiple options how to solve this - RAG, LLM training or cache. I picked the latter for simplicity.
Large Language Models are getting better every day, but imperfect today. We should not forget about it.
Limitations
For me Kaisim is just an experiment and it currently has various limitations, but they can be fixed.
No memory
Right now Kaisim is a goldfish - it does not remember any previous interactions. So if you created a resource, it will not show it to you in the next run. It can be fixed with RAG, context enrichment or enabling memory in CrewAI.
Custom Resource Definitions (CRDs) are not supported
This limitation comes from caching the api-resources. There is a workaround - upload your own API resources through /cache endpoint. Like if you currently have a k8s cluster with some CRDs, you can query api-resources and groups from the cluster and upload to cache.
Fetch resources from a real Kubernetes cluster:
curl –server="https://you_real_k8s" –token=”token" /apis
curl –server=”https://you_real_k8s” –token=”token" /apis/path/to/crdUpload them to Kaisim API:
curl -H “Authorization: Bearer TOKEN” \
https://api.kais.im/cache \
-d ‘{“api_path”: “/api”, “response”: “YOUR RESPONSE}’Cached responses defined by the user are prioritized. Also see the following scripts that can help you to understand how cache works: fetch_predefined_api.py and init_cache.py
Exec does not work
When you run kubectl exec, not only it runs an API call, but also opens a websocket stream between the shell of the container and kubectl client. It is a bit challenging to mimic this behavior right now.
Rate limiting
It is an experiment for me, so I enforced rate limiting on api.kais.im endpoints and LLM calls. Right now you will not be able to run more than 5 LLM backed calls per minute per token or IP address. They are configured in the models.py, but I also enforce rate limiting on nginx to avoid app overload. You can of course take the app and run it yourself :)
Possibilities (instead of conclusion)
So, we've messed around with Kaisim, faking the Kubernetes API. But honestly, that's just a tiny peek, right? We've seen how GenAI can whip up decent responses, juggle API calls, and even throw in some hilarious errors. And that's where things get interesting.
Forget just Kubernetes. What if we could simulate everything? Think dynamic, smart simulations for any API, any system. Not just static answers, but stuff that reacts and changes like the real deal.
Want to test your app against a database that's having a bad day? GenAI can do that. Need to see how your services handle a traffic spike or a meltdown? Simulate it. Want to train new folks on a tricky platform without breaking anything? Build a virtual playground.
This isn't just about learning or testing. It's about opening up a whole new world of messing around and figuring things out. We can build these wild virtual spaces where we can try anything, learn, and build without hitting real-world walls.
Imagine:
- Instant Chaos Testing: Throw simulated network gremlins or database hiccups at your app, see how it holds up.
- API Sandboxes: Play with complex APIs without actually touching them, learn the ropes.
- Custom Learning Labs: Build simulations that teach you at your own pace, with feedback that makes sense.
We're not just faking APIs; we're faking possibilities. The hiccups we hit now? Just stepping stones. Let's start tinkering, building, and seeing just how far we can push this GenAI simulation thing. The real fun's just starting.